

Apache Hadoop is an open-source big data framework written in Java. It stores and processes humongous amounts of data. Hadoop is licensed under Apache License 2.0.
Before discussing the best Hadoop interview questions for 2026, let's know a little more about Hadoop.
The name Hadoop comes from an interesting fact that Doug Cutting, one of the creators of Hadoop, named it after his son’s toy elephant. The other creator is Mike Cafarella. It was first developed in 2005 to support distribution for another project. Hadoop has the following main modules:
- Hadoop Common – This is the collection of all the common libraries and utilities that support other Hadoop modules.
- HDFS (Hadoop Distributed File System) – It is a distributed file system that stores data in commodity machines.
- YARN – It manages computer resources in clusters and schedules user operations.
- MapReduce – It is responsible for processing and classification of huge datasets.
The Hadoop platform also includes projects like Apache Pig, Apache Hive, Sqoop, Apache Hbase, Flume, and Oozie, each of which performs certain unique functions.
Big Data and How Hadoop Handles It?
Big data is nothing but vast sets of user data. Data can be obtained from various sources like online shopping, web browsing, survey forms, and job portals. Conventional data systems are not efficient in dealing with these huge datasets, and that is why Hadoop has become a good choice for storing and processing big data.
HDFS, the file system of Hadoop, uses block architecture to handle large files, i.e., files having a size greater than 64 or 128MB. The humongous files are split into files of lesser size (i.e., 64MB and 128MB) and stored in HDFS.
This way, the processing can be done on the split data using the map-reduce (mapper) function. MapReduce performs mapping, processing, combining, sorting, and reducing. Companies also use Mahout to perform predictive analysis. RHadoop and Hadoop with Python are the most popular ways for processing, mining, and analyzing big data.
Features of Hadoop
- It is open-source.
- Hadoop is highly scalable and responsive.
- It offers high availability and fault tolerance.
- Hadoop provides faster data processing.
- It can work with commodity hardware. Therefore, there is no requirement for high-end hardware.
- It can process raw (unstructured) as well as structured data.
- Hadoop scales linearly. Therefore, one Hadoop cluster can have as many as thousands of servers.
- It works on the principle of writing once, read anywhere (WORA).
Top Hadoop Interview Questions and Answers
Here are the most common Hadoop interview questions and answers, categorized into three levels, Basic, Intermediate, and Advanced.
Basic Hadoop Interview Questions
1. What is big data? Explain the characteristics of big data.
Answer: Previously, there used to be limited data, and one storage unit and processor were enough to store the entire data. However, with everything becoming digital, there is a humongous amount of data generated every hour, for which a single processing or storage unit is not sufficient.
The data nowadays also come in different formats and has to be processed before any sense can be made out of it. Such data that cannot be processed using traditional processing and storage methods are called big data. It is defined by the following six characteristics (6 Vs):
- Volume – The amount of data from various sources.
- Velocity – The speed at which the data is generated.
- Variety – Different types of data, namely structured, unstructured, and semi-structured data.
- Veracity – How much can we trust the data?
- Value – The potential business value of the data.
- Variability – The various ways to format and use the data.
2. What are the main components of the Hadoop ecosystem?
Answer: Hadoop ecosystem is a platform to solve big data problems. It has several services that work together to solve the problem. The components are:
- Hadoop Distributed File System (HDFS)
- Yet Another Resource Negotiator (YARN)
- MapReduce (Sort and process data)
- ZooKeeper for cluster management.
- Spark for in-memory processing of data.
- Pig and Hive to develop queries and scripts for data processing.
- Lucene for indexing and searching.
- Hbase is a NoSQL database.
- Mahout is a library for machine learning algorithms.
- Oozie for job scheduling
| Oozie, Flume, and Zookeeper | Data Management |
| Hive, Pig, Sqoop, and Mahout | Data Accessing |
| YARN and MapReduce | Processing the Data |
| HDFS and Hbase | Data Storage |
3. Explain the architecture of Hadoop .
Answer:
The main components of
Hadoop architecture
are NameNode and DataNode. HDFS follows a master-slave architecture. Each cluster has one master node and multiple slave nodes.
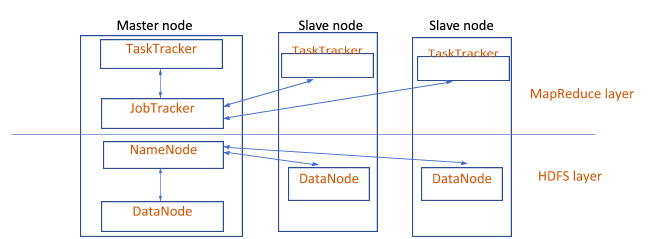
HDFS stores the application data and file system metadata on dedicated servers. DataNode stores the application data, and NameNode stores the file system metadata. The file content is replicated across multiple DataNodes, ensuring high availability and reliability.
NameNode and DataNode communicate using the TCP protocol. Once a client submits a job, the JobTracker splits and assigns it to multiple TaskTrackers. A TaskTracker invokes the Map function, and upon completion of the task, it notifies the JobTracker.
Once the Map phase is done, the JobTracker again selects TaskTrackers for executing the reduce function.
4. What is the underlying architecture of the Hadoop cluster?
Answer: Hadoop cluster is a network of computers connected through LAN. We use it to store and process large data sets. The cluster follows a master-slave architecture. The masters are the daemons like NameNode and Resource manager. The slaves are DataNode and Node manager.
5. Explain the difference between single-node and multi-node Hadoop clusters.
Answer: The following table describes the major differences between single-node and multi-node Hadoop clusters:
| SINGLE-NODE | MULTI-NODE |
| The daemons like NameNode and DataNode run on the same machine. | Follows master-slave architecture where NameNode runs on the master machine, and DataNode runs on slave machines. |
| All the processes run on one JVM instance. | Master machines are powerful and fast, whereas slave machines are cheap. |
| No configuration is required other than setting the JAVA_HOME environment variable. | Slave machines can be present anywhere. Their configuration changes are based on the machine. |
| The default factor is 1. | The default factor is more than 1. |
6. State some differences between a relational database and Hadoop.
Answer: The following table highlights the key differences between a relational database and Hadoop:
| RDBMS | Hadoop |
| It deals with structured data. | It deals with structured, unstructured, and semi-structured data. |
| An RDBMS can store low to medium amounts of data. | It can store huge amounts of data. |
| Reads from the database are quite fast. | Read and write operations both are fast in Hadoop. |
| Relational database management systems use high-end servers. | Hadoop uses commodity hardware. |
| It provides vertical scalability. | Hadoop offers horizontal scalability. |
| An RDBMS has higher throughput. | Throughput is low in Hadoop. |
| It is system software that creates and manages databases based on a relational model. | It is open-source software that connects various computers to solve complex problems with a lot of processing and computation. |
7. Describe the structure of HDFS and how it works.
Answer: You can read about the HDFS structure in detail on the official Hadoop website . This is one of the most crucial Hadoop interview questions, and that’s why you should know about it in detail.
8. What is the difference between copyToLocal and copyFromLocal commands?
Answer:
- copyFromLocal – Copies from a local file source.
- copyToLocal – Copies to a local file destination.
9. Why does HDFS store data using commodity hardware?
Answer: It provides high availability and fault tolerance of data even in case of machine failure and provides distributed processing as every DataNode has some process to do. Further, storing data on commodity hardware is cost-effective.
10. Since Hadoop contains massive datasets, how can you ensure that the data is secure?
Answer: Hadoop secures the data using three A’s:
- Authentication – The user should be authenticated using a valid username and password.
- Authorization – After authentication, the permissions that are given to the authenticated user are defined using authorization. For example, read permission and write permission.
- Auditing – Through auditing, we can track the activities of each authenticated user for their activities. Every activity is recorded.
Other than these, Hadoop uses data encryption and data masking to prevent unauthorized access.
Hadoop Interview Questions - YARN
11. Which Hadoop version introduced YARN? How was resource management done before that?
Answer: Hadoop version 2.0 introduced YARN in 2012. Before this, resource management was performed by MapReduce using a single JobTracker (master).
12. What are the components of YARN?
Answer: The following are the main components of YARN:
- Resource manager – It manages the resource allocation in the cluster.
- Node manager – It is responsible for task execution on DataNode.
- Application master – It monitors task execution and manages the lifecycle and resource needs of each application.
- Container – It contains all the resources like CPU, RAM, and HDD on a single node.
13. Explain the benefits of YARN.
Answer: It is scalable, flexible, and efficient as it shares the responsibilities of MapReduce.
Hadoop Interview Questions - Hbase
14. What is Hbase? What are the benefits of Hbase?
Answer: Hbase is a database built over HDFS. It uses a hashtable, provides random access, and stores data in indexed HDFS files that provide faster lookup for database tables. The main advantage here is that Hbase is very fast, and we can use it for heavy applications for fast random access.
15. Where does Hbase dump all the data before performing the final write?
Answer: Hbase dumps all the data into Memstore, which is a write buffer.
16. Explain how the Hadoop system stores the data.
Answer: Data is stored in Hadoop using the HDFS. It replicates the data onto different nodes. If there are n nodes on your cluster, the data will be stored as blocks across the nodes.
17. Write simple Hbase commands to import the contents of a file into an Hbase table.
Answer: You can do this by using the ImportTsv command:
bin/hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.separator=”,” -Dimporttsv.columns=HBASE_ROW_KEY,mytable <path to the file from root>
18. How does MapReduce work ?
Answer: MapReduce has various phases to handle data. They are:
- Input reader – It reads the incoming data.
- Map function – It processes input key-value pairs and generates another set of (output) key-value pairs.
- Partition function – It assigns the right reducer for each map function.
- Shuffling and sorting – Data is shuffled and sorted to make it ready for the reduce function.
- Reduce function – It generates the output by assigning the reduce function to each sorted key.
- Output writer – It writes the output to a stable storage system.
19. What are the components of a MapReduce job?
Answer:
- Mapper class – It should extend the org.apache.hadoop.mapreduce.Mapper class and implement the map() method.
- Reducer class – It should extend the org.apache.hadoop.mapreduce.Reducer class.
- The driver (main) class has job configuration parameters.
20. What are counters in MapReduce? What are their types?
Answer: Counters provide statistical information about the MapReduce job. This helps in debugging any issues that occur in the MapReduce processing. There are two types of counters:
- Hadoop built-in counters – MapReduceTask, FileInputFormat, FileOutputFormat, FileSystem, and Job.
- User-defined counters – Can be written by developers in any programming language.
21. What does the ResourceManager include?
Answer: ResourceManager includes:
- Scheduler – It allocates resources to all the running applications based on queue, capacity, and other constraints.
- Applications Manager – It accepts job submissions, negotiates the first container for executing ApplicationMaster (per application), and provides service to restart ApplicationMaster if any failure occurs.
22. What is the purpose of a distributed cache?
Answer: It is a system where random access memory (RAM) is pooled from various networked computers into one in-memory data store used as a data cache for faster data processing.
23. Explain how word count is done using the MapReduce algorithm.
Answer: Apache Hadoop's official documentation explains this Hadoop interview question very well, along with the source code. Check it out from the above direct link.
24. How can you improve the efficiency of the MapReduce algorithm?
Answer: There are many ways to enhance the efficiency of MapReduce – by using a combiner, by using compression libraries, optimizing the configuration parameter settings, filtering the data at the map stage itself, using the right profiling tools, etc.
25. What is Mahout? How does it help in MapReduce algorithms?
Answer: Mahout is a machine learning library running on top of MapReduce. With Mahout, MapReduce jobs can just refer to the predefined ML algorithms rather than manually implementing them. Thus, it reduces much overhead for developers.
26. Is it possible to write MapReduce programs in a language other than Java?
Yes, we can do so through a Hadoop utility API called Hadoop Streaming. It supports Python, C++, R, Perl, and PHP.
27. What is Hive Query Language (HiveQL)? Give some examples.
Answer: It is a query language similar to SQL and has a similar syntax to SQL. Some examples of HiveQL are:
- Select query – select * from student;
- Create table – create table student(ID INT, Name STRING, Address STRING, marks FLOAT, major_subject STRING);
- Create table for xml data – create table xml_student(details STRING);
28. How to create partitions in Hive?
Answer: To create partitions in Hive, use the following command:
CREATE TABLE table_name (column1 data_type, column2 data_type) PARTITIONED BY (partition1 data_type, partition2 data_type,….);
Example
CREATE TABLE student (name STRING, percent FLOAT, year_birth INT) PARTITIONED BY (year_birth INT);
29. What are the differences between static and dynamic partitioning?
Answer: The following table draws all the major differences between static and dynamic partitioning:
| Static Partitioning | Dynamic Partitioning |
| It is the process of inserting input files individually into a partition table. | It is a single insert into the partition table. Dynamic partitioning loads data from a non-partitioned table. |
| Static partitioning is less time-consuming. | Dynamic partitioning requires more time to load data. |
| Here, partitions can be altered. | A partition cannot be altered in dynamic partitioning. |
| You need to set the property hive.mapred.mode = strict in hive-site.xml. | In dynamic partitioning, set the hive.mapred.mode property to non-strict. |
| To set a limit, the where clause should be used. | There is no requirement for the ‘where’ clause. |
| Static partitioning is most suitable for loading big files in Hive tables. | Dynamic partitioning is more suitable when large amounts of data are stored in a particular table. |
30. How do you handle the situation where partitioning is not possible?
Answer: When partitioning is not possible, we use bucketing. It divides large datasets into smaller parts called buckets. The bucketing concept is based on the hashing technique.
Intermediate Hadoop Interview Questions
31. What is a daemon?
Answer: Daemons are processes that run in the background. In Hadoop, there are six daemons:
- NameNode
- Secondary NameNode
- DataNode
- JobTracker
- TaskTracker
- JobHistoryServer
32. Name the various daemons in Hadoop and their functions in the Hadoop cluster.
Answer: There are two types of daemons in Hadoop, namelyHDFS and YARN daemons. HDFS daemons:
- NameNode – It is the master node that stores the metadata of all the files and directories.
- DataNode – It is the slave node containing the actual data.
- SecondaryNameNode – It comes into action when there is a failure in NameNode. It merges the changes with the filesystem image (fsImage) present in the NameNode and stores the modified fsImage into persistent storage.
YARN daemons:
- ResourceManager – It manages all the resources and schedules applications running on top of YARN.
- NodeManager – It runs on a slave machine, reports to the ResourceManager, launches application containers, and monitors their resource (memory, disk, CPU, network, etc.) usage.
- JobHistoryServer – It maintains information about MapReduce jobs once the application master terminates.
33. Explain active and passive NameNodes.
Answer: Active NameNode is the primary name node that executes in the cluster. Whenever the active name node is down, passive NameNode replaces it in the cluster. The passive NameNode is thus a standby NameNode and has the same metadata as the active NameNode.
34. How are NameNode and DataNode related?
Answer: The NameNode is the master node in the HDFS. There is only one name node, and it contains the location of all the data nodes and other information like the number of blocks and the location of replications. The corresponding slave node for this master is the data node that stores data as blocks.
35. What is the jps command in Hadoop?
Answer: JPS or Java Process Status uses the Java launcher on the host to find the classes and arguments that are up and running (passed to the main method).
~$jps <hostname>
36. How to perform join in HiveQL?
Answer: There are four types of joins in HiveQL: inner, right outer, left outer, and full outer. For example, if you have two tables as customer and order, then,
SELECT c.ID, c.NAME, o.AMOUNT FROM CUSTOMERS c LEFT OUTER JOIN ORDERS o ON (c.ID = o.CUSTOMER_ID);
It will give all the values in the left table (customers) and the matched values in the right table (orders), whereas
SELECT c.ID, c.NAME, o.AMOUNT FROM CUSTOMERS c RIGHT OUTER JOIN ORDERS o ON (c.ID = o.CUSTOMER_ID);
It will give all the records of the right table (orders) and the matched records of the left table (customers).
SELECT c.ID, c.NAME, o.AMOUNT FROM CUSTOMERS c FULL OUTER JOIN ORDERS o ON (c.ID = o.CUSTOMER_ID);
This will give all the records of both tables.
SELECT c.ID, c.NAME, o.AMOUNT FROM CUSTOMERS c JOIN ORDERS o ON (c.ID = o.CUSTOMER_ID);
It will select only the matching values from both tables.
37. What is SequenceFileInputFormat in MapReduce?
Answer: It is an input format that reads sequence files, i.e., binary files that are block-compressed, and stores sequences of key-value pairs.
38. What are the different types of InputFormat in MapReduce?
Answer: There are four types of InputFormat in MapReduce. These are:
- FileInputFormat (for file-based input formats)
- TextInputFormat (default)
- KeyValueTextInputFormat (contains text as key-value)
- SequenceFileInputFormat (reads sequence files)
39. Explain how Apache Pig is better than MapReduce.
Answer: Apache Pig is better than MapReduce for the following reasons:
- Any programmer with basic SQL can work with Apache Pig. However, for MapReduce, Java knowledge is a must.
- It is easier to perform join operations using Apache Pig.
- The length of the code is significantly reduced because of the use of the multi-query approach in Apache Pig.
- Apache Pig doesn’t require compilation as the operators are internally converted to MapReduce jobs.
40. What are the different run modes in Pig?
Answer: There are six-run modes in Pig – Running Pig
41. Explain the embedded mode in Apache Pig.
Answer: Pig allows developers to define their functions (user-defined functions) and use them in the script. This is the embedded mode.
42. Give an example of how Pig Latin is used for analyzing and processing data.
Answer: Pig Latin is used to analyze Hadoop data using Apache Pig. It provides various methods such as load, store, filter, distinct, generate, stream, joins, group, order, split, explain, and describe for data loading, transformation, and manipulation.
43. Enumerate the languages supported by Pig UDF.
Answer: Pig supports Java, Python, Jython, JavaScript, Ruby, and Groovy.
44. What is a Zookeeper?
Answer: Zookeeper is a service for distributed systems that offers a hierarchical key-value store that can provide distributed services like naming registry, synchronization, and configuration services.
Advance Hadoop Interview Questions
45. Explain some differences between RDBMS and Hbase.
Answer: Although both are database management systems, there are many differences between the two. The following table enumerates the important differences between RDBMS and Hbase:
| RDBMS | Hbase |
| It has a fixed schema. | There is no fixed schema in Hbase. |
| It requires structured query language (SQL). | It doesn’t require SQL. |
| An RDBMS is row-oriented. | Hbase is column-oriented. |
| A relational database is not so scalable. | It is highly scalable. |
| Data retrieval is slow. | Hbase offers fast data retrieval. |
| It can handle structured data. | It can handle structured, unstructured, and semi-structured data. |
| A relational database management system follows ACID (Atomicity, Consistency, Isolation, and Durability) properties. | It follows CAP (Consistency, Availability, and Partition-tolerance) properties. |
46. What is PySpark? What are some of its features?
Answer: PySpark is an API developed by Apache Spark foundation to enable Python programmers to work with Apache Spark. Python is a powerful language for exploratory data analysis. Features of PySpark are:
- Ease of maintenance of code.
- Better data visualization options than other languages like Scala and Java.
- Helps interface with Resilient Distributed Datasets (RDD).
- Dynamic interface with JVM objects using Py4J .
- Loads of external libraries like PySparkSQL, MLLib, and GraphFrames to perform data analysis and ML tasks.
47. How are Apache Spark and Apache Hadoop related?
Answer: Both Hadoop and Spark process large datasets. Spark is written in Scala, whereas Hadoop is written in Java. Spark is many times faster than Apache Hadoop. Also, Spark is easier and more compact to use than Hadoop.
Hadoop, on the other hand, has a lengthy and complex architecture. Hadoop doesn’t support caching, whereas Spark caches data in memory, thus giving better performance. In Hadoop, data processing happens in batches, whereas Spark can do it in many modes like batch, iterative, graph, interactive, and real-time.
48. What is HCatalog? What formats does it support?
Answer: HCatalog is a table and storage management layer that enables developers to read and write grid (tabular) data with ease. With HCatalog, users don’t have to worry about the format in which their data is stored. HCatalog supports RCFile, JSON, CSV, and SequenceFile formats by default. Check out this doc from Cloudera for more information.
49. Which component of the Hadoop ecosystem facilitates data serialization and exchange?
Answer: Avro, which is a language-neutral data serialization system, facilitates data serialization and exchange in the Hadoop ecosystem.
50. What is the purpose of Apache Sqoop? How does it work?
Answer: It is designed to transfer bulk data between Apache Hadoop and other external databases like RDBMS and enterprise data warehouses. Sqoop uses import and export commands for data transfer, and internally it uses MapReduce programs to store datasets to HDFS.
51. How does Oozie control the Hadoop job workflow?
Answer: In Oozie, workflow is a collection of actions. These actions like the MapReduce jobs and pig jobs are placed in a control dependency direct acrylic graph (DAG). The second action cannot start until the first action completes successfully. This is called the control dependency. The control flow nodes describe the start and end of the workflow.
52. How does Hadoop handle failovers? How was it done in Hadoop 1 and 2?
Answer: In Hadoop 1.0 and 2.0, the single point of failure was the NameNode, i.e., if the NameNode failed, the entire system would crash, and bringing the secondary NameNode for getting the Hadoop cluster up was a manual task! Now, Zookeeper provides automatic failover, thus ensuring high availability.
53. What is Hbase compaction? What are its types?
Answer: Hbase compaction is a process through which Hbase cleans itself. Compaction is of two types, major and minor.
- Major compaction – It is the process of combining x number of smaller Hfiles into a single large Hfile, where x is a configurable number.
- Minor compaction – It is the process of combining StoreFiles of various regions into a single StoreFile.
54. What is data locality in Hadoop?
Answer: In data locality, rather than moving large datasets to the place where computation is done, computation is moved close to the place where the actual data is. Data locality improves the performance of the system.
55. What is the importance of hdfs-site.xml?
Answer: It is a configuration file that contains settings for NameNode, DataNode, and SecondaryNode. These configuration settings load during the runtime.
56. How does Hadoop HDFS perform indexing?
Answer: Indexing depends on the block size. Index files are stored in a directory folder where actual data is present, i.e., the memory of the HDFS node. Search is done on the index file that resides in the memory using the RAM directory object.
57. Can you write a custom partitioner for a MapReduce job? How?
Answer: Yes, we can write it using our implementation of org.apache.hadoop.mapreduce.Partitioner.
58. How do you determine the number of mappers and reducers running for a MapReduce job?
Answer: The number of mappers can be controlled by changing the block size, which changes the size of the input split: N(mappers) = total data size/input split size So, if the data size is 1Tb and the input split size is 100MB, then, N(mappers) = 1000*1000/100 = 10,000 The number of reducers can be set using Job.setNumreduceTasks(int).
59. What is Apache Flume? What is its use?
Answer: Flume helps to move huge quantities of streaming data into HDFS. The most common example is that Flume collects log data from log files on the web servers and aggregates them in HDFS. The collated data can then be used for analysis by the Hadoop cluster.
60. What is rack awareness? What does it improve?
Answer: Rack awareness is a concept used by NameNode to choose the DataNode that is on the same rack or the nearest rack for reading or writing of data. The rack is a collection of 40 to 50 data nodes that are connected through one network switch. Hadoop cluster contains many racks for high availability. Communication between data nodes residing on the same rack gives high performance and reduces the network traffic.
Conclusion
Hadoop is not a tough topic. However, it is vast and involves knowledge of many components put together. You should know about each of them to be able to explain the architecture to the interviewer. Most of the concepts are straightforward.
The above set of Hadoop interview questions entails the most commonly asked questions. Nonetheless, the list is not exhaustive. Also, the same question may be asked differently, so be alert and understand the question thoroughly before you give your answer.
The questions also vary based on your experience, and our list contains questions from various experience levels asked by different interviewers. Knowing about MongoDB, Flume, Storm, and Java will give you a definitive edge over other candidates.
People are also reading:


