

If you are new to machine learning, we suggest you read our articles about machine learning and supervised learning . If you know about them both, you can quickly understand unsupervised learning as well.
What is Unsupervised Learning?
In unsupervised learning methods, data is fed to the system. The machine classifies, sorts, groups, and finds patterns on its own without any human intervention. This is unlike supervised learning, where we label or classify the inputs. Thus, unsupervised methods can solve complex problems and can group the data based on similarities or differences on their own. There is no prior training involved.
For example: A child sees many people around. How does the child differentiate between other children, adults, and the elderly? You wouldn’t point to each person and label them. Rather, the child will observe and find similar characteristics, for example, hair, body built, height, voice and other features to categorize people into different age groups. Compared to supervised learning, unsupervised learning is more difficult. Since we have nothing to compare or label, we need experts to find out whether the insights are useful or not. Further, the algorithm may pick some categories that may confuse the algorithm and produce irrelevant results. Let us take a simple example: Suppose you feed data containing bats and balls. Unsupervised learning can sort bats and balls based on the characteristics of each, however, it might add more categories like color. Now the question is, will it sort on the basis of color or on the basis of the object type? This makes unsupervised learning a little more unpredictable compared to other machine learning methods. Despite this, unsupervised learning is considered useful and important because:
- It can find many classes and patterns in data that may not be possible otherwise.
- Labeled data needs human intervention, but unlabeled data doesn’t, so this method is more suitable for real-time data.
- Labeling huge datasets also involves a lot of time and cost, so only a few samples can be labeled manually.
Types of Unsupervised Learning
There are many types of unsupervised learning, which come under 3 broad categories:
1. Clustering
– Clustering involves sorting the data into various groups (called clusters) based on their similarities. Each cluster has similar items and differs from other clusters. Also, the features for distinction can be anything like color, shape, and size.
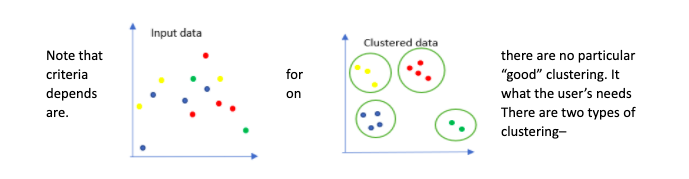 2. Hard clustering
– In this type, every data point either belongs to one cluster completely or not. The above example of colors is hard clustering.
3. Soft clustering (Fuzzy clustering)
– Here, instead of putting the data points strictly into a cluster, the likelihood of the data point belonging to a particular cluster is assigned. So, each data point will have a probability (less or more) to be assigned to any of the clusters.
2. Hard clustering
– In this type, every data point either belongs to one cluster completely or not. The above example of colors is hard clustering.
3. Soft clustering (Fuzzy clustering)
– Here, instead of putting the data points strictly into a cluster, the likelihood of the data point belonging to a particular cluster is assigned. So, each data point will have a probability (less or more) to be assigned to any of the clusters.
Unsupervised Learning Algorithms
Based on the concept of unsupervised learning, there are 100s of algorithms. Obviously, some are more popular than others. We will discuss some of the most popular algorithm types, which are:
- Connectivity models – In this type of model, we consider that the data points that are closer to each other have more similarities than the data points that are far. Moreover, these models are useful for small datasets. Either all the data sets are first classified and then put into various clusters, or all data points are put into a single cluster and then divided as the distance increases.
- Distribution models – These models work on the probability that all the data points of a cluster come under the same distribution.
- Density models – The data points are separated as per regions of different density and the data points within certain regions are put into one cluster. An example of this model is DBSCAN.
- Centroid models – These models are iterative and the number of clusters to be created should be decided in the beginning i.e. we should know the dataset. To determine the similarities, the model considers the proximity of data points to the centroid of the clusters.
- Hierarchical models – This type of model creates a tree structure. The structure can be either top-down or bottom-up. Initially, the model treats each data point as a cluster. As we iterate, we can combine two clusters based on the distance between them (smallest). This process is repeated until we reach the root, that is when all the data points will be in one cluster. We can build the other clusters similarly.
1. K-means Clustering
It is an efficient algorithm based on the centroid model. We choose k number of points (clusters) in the beginning. Next, assign all the data points that are nearest to each of the k clusters to the corresponding cluster and then calculate the mean of all the points that belong to the cluster (centroid). The value will become the next centroid. We repeat the process until the centroid value remains constant. Once this happens, it means that all data points have been grouped. The main issue with this unsupervised learning algorithm is that it has a high variance. Thus, the performance is not as good as other powerful unsupervised learning algorithms.
2. DBSCAN
Clusters are not always in circles or spheres. They can take any other shape and size too. This is the main idea behind DBSCAN. Also, DBSCAN doesn’t need you to define the number of clusters beforehand. It can also identify noise and doesn’t include it in any of the clusters. Moreover, it chooses the starting point randomly. After this, we can get the neighbors of this selected point, and if there are sufficient neighbors, clustering can happen. All the neighbors of the selected point become a part of the cluster. Same way, other clusters are formed. If a particular neighbor is, however, too far away from the arbitrary data point, it is considered as noise.
3. EM (Expectation-Maximization) Clustering Using Gaussian Mixture Models
In this method, we use both the mean and standard deviation to form the cluster, thus giving it an elliptical shape. The data points are assumed to have Gaussian distribution. GMM is a very flexible model because one data point can belong to multiple clusters. To determine the class of an overlapping data point, we can just measure the probability of the data point to both the classes and choose the higher value. Clustering algorithms are widely used:
- To detect anomalies in data. For example, a customer who is randomly liking a lot of pages on Facebook in a short time.
- For image compression and face detection.
- To merge points in a map that are close together.
- For market segmentation. For example, identify customers who like to buy coke along with pizza and separate them from those who like to order fries with pizza.
4. Generalization (Dimensionality Reduction)
Generally, in classification problems, there are many random variables or features. As the number of features increases, the complexity of the model increases and so does the training time. If features are correlated, then adding so many features becomes redundant. By using dimensionality reduction, we can reduce the number of random variables (features) and obtain a set of ‘principal’ variables. Dimensionality reduction has 2 components:
- Feature extraction (reduces the high-dimensional data to lower dimension) and
- Feature selection (find a smaller subset of the original set of features).
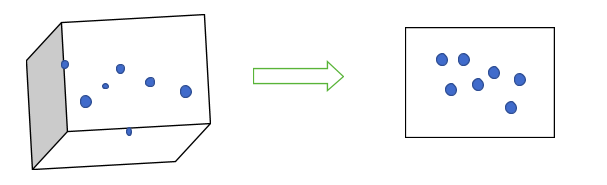 Dimensionality reduction methods can be linear or nonlinear.
Dimensionality reduction methods can be linear or nonlinear.
5. Principal Component Analysis (PCA)
PCA is a linear method for dimensionality reduction. It is based on the principle that the variance of data when it is reduced from higher dimension space to lower dimension (for example, 3D to 2D, or 2D to 1D) should be maximum. Principal component analysis helps in reducing the storage space through data compression and reduces overall computation time other than removing redundant features. This is done by transforming the variables into a set of principal components (another set of variables). These variables are orthogonal (zero correlation) because the principal components are eigenvectors from a covariance matrix. This ensures that the variance retains even with the reduced dimensions.
6. Singular Value Decomposition (SVD)
SVD is the most common method for matrix decomposition (factorization). In this method, the original matrix is split into two smaller matrices as, A = U x D x VT Here, U and V are smaller matrices and D is the diagonal matrix. VT is the transpose of the matrix V. SVD works on both square and non-square matrices and the matrices U and V are orthonormal. It can be used for data reduction, Principal Component Analysis (PCA), least-squares linear regression, removing noise from data, and compressing images. The most important use of SVD is in a movie recommendation system where the ratings for movies are sparse. For example, 100 users would have watched a movie, but only 10 would have reviewed it. For such sparse data, SVD provides a good way of factorization and completion of data.
7. Random Forests
Random forests are great algorithms for feature selection. We can create a large set of trees and find the most informative subset of trees. With that, we can reduce the number of trees (levels) to only those that do not have similar features. It is an easy and efficient way to identify the features that are most predictive compared to other features. There are many other methods for dimensionality reduction , but these are the most performant ones. Some of the most useful applications of dimensionality reduction are:
- Collaborative filtering and recommender systems,
- Text mining,
- Customer relationship management, and
- Face and handwriting recognition.
8. Association Rules
Association algorithms find links or patterns in the data and build a predictive model based on strong rules. A simple example would be market basket analysis, where if a person purchases rice and some lentils, she would also most likely purchase salt and some other spices. On the other hand, if a person purchases bread, she is also likely to purchase butter, eggs or jam. All these show the typical association of one item with the other related items through data mining.
| Customer 1 | Bread, Butter | Associations |
| Customer 2 | Bread, Eggs | {Bread, Eggs} |
| Customer 3 | Bread, Butter, Eggs | {Bread, Butter} |
| Customer 4 | Milk, Eggs | {Milk, Eggs} |
| Customer 5 | Milk, Bread, Eggs |
Some popular association rule algorithms are:
I. Apriori
This algorithm powers the ‘You may also like’ section on Amazon and other e-commerce websites. Apriori is a simple algorithm wherein through data mining, associations and patterns can be formed about the data. The name comes from prior knowledge of the properties of items that can be bundled together. The most common use of this algorithm is seen in market basket analysis, however, it can also be used in detecting common medical conditions and diseases. There are 3 steps to calculate the association rule:
- Support – It tells us about the items that are frequently bought together.
Support = frequency (A, B)/N Items with low fractions can be filtered out with this step.
- Confidence – Suppose most users purchase items A and B together then Confidence tells us the number of times A and B are bought together, given the number of times A is bought.
Confidence = frequency (A, B)/frequency(A) This filters those items that have less frequency in comparison to others. For example, if A is bread and B is butter, and there is C that represents jam, and the confidence for A and B is way more than A and C, then we can filter out A and C.
- Lift – Even after support and confidence, there might be many records left. Thus, we calculate the lift to create the final association rule. Lift tells us about the strength of any rule. Also, a higher lift value indicates a better association. For example, if a person buys bread and the chances of buying eggs are twice, the lift value will be 2.
II. FP-Growth
Frequent Pattern (FP) growth algorithm is an improvement over the Apriori algorithm. The algorithm creates a frequent pattern tree to represent the database and the tree depicts the association between different itemsets. One frequent item is used to fragment the data. Also, each fragmented pattern’s itemsets are analyzed and the most frequent patterns are identified. Unlike Apriori, which needs database scans for each iteration, FP growth creates a tree structure by scanning the database only twice. Every node of the tree indicates one item of the itemset. The first node (root) is null, and the subsequent nodes represent itemsets. It is a scalable algorithm, however, it is more expensive in comparison to Apriori.
III. ECLAT
ECLAT or Equivalence Class Clustering and bottom-up Lattice Traversal is another more scalable version of the basic Apriori algorithm. As the name suggests, it follows the bottom-up approach, which makes it a faster algorithm. It needs less memory as it follows the depth-first approach. Association algorithms are typically used to:
- To analyze browsing patterns of users.
- To predict sales and discounts.
- For targeted advertising.
- To place products on the racks in a shop. For example, keeping bread and eggs on the same rack.
Summary
In this article, we introduced you to the most important concepts in unsupervised learning. If you are just beginning your career as a data scientist or machine learning engineer, this introduction will provide you a good start to you. Check out our list of best machine learning books to get in-depth knowledge about these algorithms and other important ML concepts. Now, let's get a quick summary of the article:
- In unsupervised learning, the machine learns without any human intervention. There are no labels, unlike supervised learning.
-
There are 3 types of unsupervised learning algorithms:
- Clustering,
- Association, and
- Generalization.
- Clustering algorithms help to group similar items based on features (random variables).
- Generalization or dimensionality reduction algorithms reduce the dimensions to eliminate redundant features.
- Association rules find links and patterns in the data for predictive analysis.
Although unsupervised learning models are unpredictable and need more data, they are extremely important because they can handle huge sets of raw and unstructured data with ease, which is, otherwise, not possible for humans.
People are also reading:
- Best Machine Learning Interview Questions
- Top 10 Machine Learning Algorithms for Beginners
- Top 10 Machine Learning Applications
- AI vs ML vs Deep Learning
- Introduction to Machine Learning
- 10 Best Machine Learning Projects for Beginners
- What is Apriori Algorithm?
- Python Data Science Libraries
- What is Data Engineering?
- Data Mining


