

Data engineering has been grabbing a lot of eyeballs of late, and rightly so – data engineers work a lot with structured and unstructured data collected from various sources. Also, they are responsible for managing complex workflows, ETL, managing pipelines, automation, data modeling, etc. Data engineers ensure a smooth flow of data between applications and servers. They architect data processing systems that can handle large-scale data-intensive applications.
What is Data Engineering?
Data engineering is that particular branch of software engineering that involves maintaining an organization’s data pipeline systems and cleaning data to make it usable for insights. Data science has now been divided into various sub-phases, like data collection, data preparation, data storage and transformation, and data analysis. Each of them contributes to the overall process of data engineering.
Data engineering covers various data science stages and deals with the collection, processing, storage, modeling, and retrieval of vast amounts of data for big data analytics. Data engineers provide a robust and durable infrastructure to store and transform data from various sources into a single warehouse.
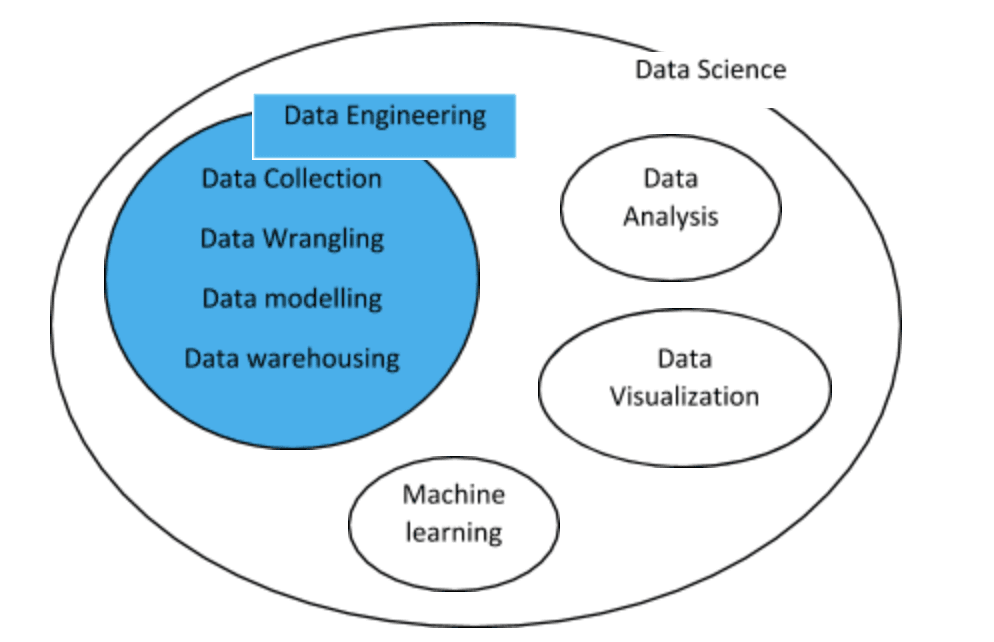
Why is Data Engineering Important?
Before data engineering, a data scientist would have to write complex SQL queries , manage datasets, and manually perform routine tasks, which consumed a lot of productive time. With data engineering practices in place, it becomes easy to develop data pipelines, store data in an organized way, ready the same to be analyzed, and automate the most mundane tasks.
ETL and data warehousing tasks can be performed using various tools. For data engineers, data is the end product, which means they make data available in the most usable format for analytics. Data engineers are aware of the business problem and process and store the data in such a way that the essential variables are retained efficiently.
How to Become a Data Engineer?
Data engineers should possess strong technical and communication skills. Most importantly, you should be adept in big data frameworks, SQL, and NoSQL technologies to process and manipulate data using various tools and techniques. Start with the following:
-
Operating systems
Familiarity with Linux or Unix environment is essential, as you will be working on a lot of scripting tasks and a command-line interface.
-
Programming languages
Find out the language that you find easy to learn. You need programming language knowledge to understand algorithms. If you are a beginner in software programming, start with Python . It will also help you grow as a data analyst or data scientist later in your career.
-
DBMS
Database Management System should be on your tips. Focus not just on writing queries but also on administration tasks, like capacity planning, DB design, configuration, installation, security, performance, backup options, failover, and recovery. The preferred database systems are Oracle Database and MySQL.
-
NoSQL
Relational databases can handle structured data well, but a data engineer has to handle a lot of unstructured or raw data, which can be handled by NoSQL databases like MongoDB.
-
ETL tools
Extract, Transform, and Load (ETL) tools like Excel help you collate data from various sources and transform it into something more usable. There are many advanced tools, like Oracle Data Integrator, SQL Server, and Apache Kafka, that you can learn for data integration and ETL.
-
Big data frameworks
To process massive datasets, tools like Hadoop, Spark, and other big data frameworks are used. As a data engineer, you should be familiar with many of them and compare the same to understand which one is most suitable for a particular project and how to use it efficiently. Some of these frameworks, like Apache Spark, are also real-time processing frameworks that help perform real-time streaming data analytics.
-
Cloud technologies
Since data is huge in volume, it cannot be stored in a single machine or server. Knowing cloud technologies will help you manage data better. Two popular cloud technologies are AWS and Azure .
Roles and Responsibilities of a Data Engineer
There are 3 types of roles for a data engineer:
1. Generalist
Generalists look after every step of the data engineering process, from data collection to data modeling and analysis. It is the right role for those moving from data science to data engineering. Generalist roles are popular in small teams or small companies.
2. Database-centric
This role is mostly set in large companies where data warehouses are enormous, and data engineers have to source data from multiple databases. Data engineers design and implement schemas. Data management and administration are the major responsibilities here.
3. Pipeline-centric
Pipeline-centric data engineers work alongside data scientists to perform EDA and analytics so that the collected data can be put to fair use. They need good knowledge of cloud and distributed systems and should possess the technical expertise to query, sort, filter, and manipulate data in various ways.
As discussed in the previous section, Data engineering is a technical role. For it, knowledge of programming, computer science, and mathematics is a must. The responsibilities are also centered around these 3 skills, apart from database management and administration tasks. In senior-level positions, data engineers have the responsibility to find inconsistencies and trends in data and communicate the same to other team members. The primary responsibilities of a data engineer are:
- Data acquisition, design, and implement data processes, architecture, and structure in sync with the business requirements.
- Use tools, programming languages, and techniques to perform EDA and data modeling. Prepare data for predictive modeling as well as prescriptive modeling. Find patterns and trends.
- Work with huge datasets to find solutions for business problems.
- Automate mundane and ordinary tasks and find ways to improve data reliability, quality, and efficiency.
- Deploy efficient algorithms, analytics, and machine learning techniques for research and project purposes.
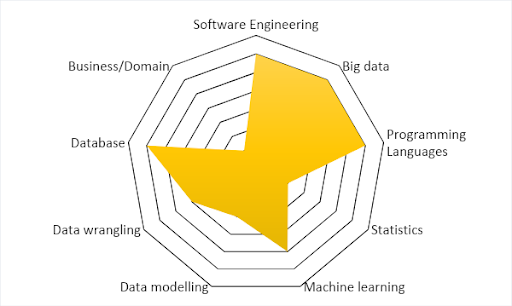
This spider chart summarizes the skills and responsibilities of a data engineer:
Job Opportunities for a Data Engineer
As per Glassdoor, a data engineer gets around $137,776 per annum on average as a salary. The exact amount depends on the location, experience level, and organization. For example, Amazon pays around $103,849, while Facebook pays about $122,695 to entry-level data engineers.
Senior data engineers get compensation anywhere between $152,000 – $194,000. Also, a lead gets above $200k per year. As the amount of data generated is increasing, the demand for data engineers and data scientists is also on the rise. Thus, it generates tremendous opportunities for skilled data engineers at various levels across the world.
Conclusion
We have not only answered the question of what a data engineer is, but also looked at how to become one. Moreover, the article also details the skill set required, the responsibilities, the type of roles, and much more about being a data engineer. Remember, the more knowledge you have, the more chances you have to get a better data engineer job with a higher salary package.
For example, Scala, Spark, data warehousing, and Java knowledge can help you get an approximately 12-13% salary hike. To start your data engineering career, be thorough with the foundational concepts: mathematics, programming, and SQL. Having big data certification can certainly be a plus.
People are also reading:


