

The job of a data scientist is much in demand in the 21st century as it is termed the “hottest job.” As companies leverage data to make strategic decisions and drive growth and success, the demand for data scientists has grown more than ever before.
Do you know?
Glassdoor ranks the data scientist as the top-third job in the United States, with a median base salary of $1.2 lakhs.
With such a high demand for these professionals, many are interested in becoming one. It is an interesting job requiring good technical knowledge and analytical skills. As this job has a broad set of roles and responsibilities, data scientists must possess diverse skills.
Here is a closer look at who a data scientist is and how to become one.
Who is a Data Scientist?
A data scientist is an analytical data expert who optimizes the organization's growth by analyzing the business from its massive volume of data, cleaning it, and then running specific AI and ML algorithms on the refined data sets to provide enhanced outcomes.
In other words, they are professionals in charge of collecting, cleaning, analyzing, and interpreting data to derive insights that help businesses make strategic decisions.
The following are their typical roles and responsibilities:
- Identifying patterns and trends in datasets to derive insights.
- Create data models and ML algorithms to predict outcomes.
- Using data-driven technologies to solve real-world problems.
- Woking in conjunction with data analysts, engineers, architects, application developers, and stakeholders.
- Analyzing data using data analysis tools .
- Staying on top of the latest trends in data science.
In a nutshell, they are responsible for the entire data science process .
How to Become a Data Scientist?
Here is a step-by-step guide to becoming a data scientist:
1. Earn a Data Science Degree
Many job descriptions mention the candidate to have a bachelor’s or master’s degree in computer science, mathematics, statistics, or any other related field.
Even if you don’t have a degree, there is another way. You can opt for online courses or bootcamps to get your leg up in the data science field and develop essential skills.
As such, various e-learning platforms have become a reasonable and efficient way to learn specialist data science skills, and that too at an affordable price.
Check out: Best Data Science Courses
2. Develop Technical and Non-Technical Skills
In the following section, we have already put together all the essential technical skills and tools you must have firsthand at.
Besides technical know-how and tools stated above, a candidate is also expected to have hands-on experience with some AI and machine learning tools.
Apart from technical skills, the following non-technical abilities are necessary:
- Attention to detail
- Organizational skills
- Problem-solving
- Desire to learn
- Resilience and focus
- Communication and teamwork
3. Work on Data Science Projects
Once you develop essential skills, it's time to put those skills into practice. Use the above tools and technical knowledge to create amazing data science projects.
When you create a few projects, it showcases your competencies in the field and in-depth knowledge. Employers can ensure that you have enough abilities to work on complex projects and have practical experience.
Check out: Data Science Project Ideas
4. Pursue an Internship
Pursuing an internship helps you work with real-world scenarios and problems you can solve with data science. You gain real-life experience working with complex datasets. Also, employers consider you a potential candidate as you hold practical experience with data science.
5. Build Your Portfolio
It is important to make an impressive first impression. Therefore, make a good quality resume. A better option is to create a website to demonstrate your work and experience. You can add your skills, certifications, working experience, and any other achievements related to the job role.
6. Build a Strong Network
Having a strong online presence and expanding your network will help you land a great job. With the help of your network, you can get a referral to renowned companies. In addition, you find more new friends and fellows with the same passion.
Go to conferences and meetups to get exposure and stay updated with your field. Although there are many such conferences and meetups, the highly popular ones are listed below:
Conferences
- The Strata Data Conference
- Knowledge Discovery in Data Mining (KDD)
- Neural Information Processing Systems (NeurlPS)
- The International Conference on Machine Learning(ICML)
Meetups
- SF Data Mining
- Data Science DC
- Data Science London
- Bay Area R User Group
7. Ace the Interview
While you build a network, focus on preparing for the interviews. There are several sites and blogs to help you with this. Some help you by providing commonly asked data science interview questions . Meanwhile, others help you by providing all essential resources and mock interviews.
Skillsets Required to Become a Data Scientist
Let us divide the skillset into two sections – Technical Know-How and Tools
Technical Know-How
1. Programming Skills
Being a data scientist requires you to be fluent in languages like Scala, Python and R . Knowledge of other programming languages like C, C++, and Java is also helpful. Python is a versatile programming language for all the steps of the data science process. It can take any data format, and SQL tables can be uploaded easily.
Check out: Python for Data Science , R for Data Science , and SQL for Data Science
2. Databases and Frameworks
They contribute massively to handling vast volumes of data. Databases like SQL and frameworks like Apache Spark and Hadoop are very much in demand in the data science industry.
3. Mathematics and Statistics
Mathematics is required to process and structure the massive data that data scientists deal with. Data scientists must be good at linear algebra, calculus, and statistics.
Statistics allows you to play with data and eventually extract insights to predict reasonable outcomes. A data scientist must know how to use statistics to infer insights from smaller data sets that apply to larger populations.
4. Data Analysis
It becomes easy to contemplate data with data analysis and thus gives more profound and more significant insights. Because of analysis, the market can be studied thoroughly, and thus, it leads to practical marketing actions.
5. Data Intuition
Companies expect you to be a data-driven problem-solver. The intuition here is not about your gut feeling. Instead, it is about the intuitive understanding of the concepts.
6. Machine Learning
It is the ability of machines to think like humans and make accurate predictions. There is a collection of machine learning algorithms to make predictions based on the data set fed.
Some Essential Algorithms You Must Master
- Linear Regression
- Logistic Regression
- Decision Tree
- Random Forest
- K Nearest Neighbor
- Clustering (for instance, K-means)
7. Natural Language Processing (NLP)
It helps computers understand human languages. It automatically manipulates human languages using various software to analyze, understand, and derive valuable insights.
8. Data Wrangling, Data Visualization, and Reporting
As a data scientist, your job is to manage large and complex data sets. This means you must clean, organize, and transform them into an understandable format, making it easy to conclude.
Further, representing conclusions from large data sets in the form of visuals make them readable and understandable by laymen. This is where data visualization comes into play.
9. Business Acumen
It combines the skills developed through experience and knowledge to solve various business issues. Data scientists not only work and analyze big amounts of data but also understand the intricacies of business organizations. They leverage their experiences and knowledge and make informed actions valuable to an organization.
Essential Tools that Aspiring Data Scientists Must Learn
Here are some essential tools that every data scientist must use and gain hands-on experience with.
1. Big Data Frameworks and Tools
- HDFS (Hadoop Distributed File System): It is the storage part of Hadoop.
- Yarn: Performs resource management by allocating resources to different applications and scheduling jobs.
- MapReduce: A parallel processing paradigm allows data to be processed parallelly on top of HDFS.
- Hive: Mainly used for creating reports, this tool caters to the professional form of SQL background to perform analytics on top of HDFS.
- Apache Pig : This high-level platform is for data transformation. It works on top of Hadoop.
- Scoop Flu : It is a tool to import unstructured data from HDFS and import and export structured data from a DBMS.
- Zookeeper : It acts as a coordinator among the distributed services running in a Hadoop environment, thus helping to configure management and synchronize services.
- Suze : It is a scheduler that binds multiple logical jobs together and helps to accomplish a complete task.
2. Real-Time Processing Frameworks
Apache Spark: This distributed real-time framework is used in the industry rigorously. It offers smooth integration with Hadoop and leveraging HDFS as well.
3. DBMS and Database Architectures
A database management system stores, organizes, and manages a large amount of information within a single software application. Thus, this helps manage data efficiently and allows users to perform multiple tasks easily. It also improves data sharing, security, and access and offers better data integration while minimizing inconsistencies.
SQL-based Technologies
SQL helps to structure, manipulate and manage data stored in relational databases . Therefore, a strong understanding is required of at least one of the SQL-based technologies listed below:
- Oracle
- MySQL
- SQLite
- IBM DB2
- SQL SERVER
- Postgre SQL
NoSQL Technologies
As the requirement of organizations has grown beyond structured data, NoSQL technology has seen an increase in the adoption rate. It can store a massive amount of unstructured, semi-structured, or structured data with quick hydration and adjoin structure as per application requirements.
Some prominently used NoSQL databases are:
- HBASE : A column-oriented database great for scalable and distributed big data stores.
- Cassandra : A highly scalable database with incremental scalability. The best feature of this tool is minimal administration and no single point of failure. Further, it is good for applications with fast and random reads and writes.
- MongoDB : A document-oriented NoSQL database. It gives full index support for high performance and replication for fault tolerance. It has a () master/slave architecture and is rigorously used by web applications and for semi-structured data handling.
4. ETL/Data Warehousing
Data warehousing is crucial when the data is fed into heterogeneous sources. As such, we need to apply ETL operations. Data warehousing is used for analytics and reporting. This is important for business intelligence solutions.
Following are the popular ETL tools:
- Talend: The major benefit of this tool is the support for big data frameworks .
- Qlik Q
5. Data Visualization
Representing valuable insights through graphical representations or visuals is a day-to-day task. So, having familiarity with data visualization tools is a must. Some popular software or platforms include:
- ggplot
- d3.js
- Tableau
Why Should you Become a Data Scientist?
Undoubtedly, data science has emerged as a flourishing, rewarding, yet challenging field. As it offers a plethora of growth opportunities, many professionals from IT backgrounds are paving their paths in this field.
Today, data has become the new oil. There is no sign of slowing down the amount of data generated these days. Every industry leverages data to provide value and maximum satisfaction to their customers, as it helps them understand their needs.
According to the data from Statista, the global big data market is expected to grow to 103 billion by 2027 .
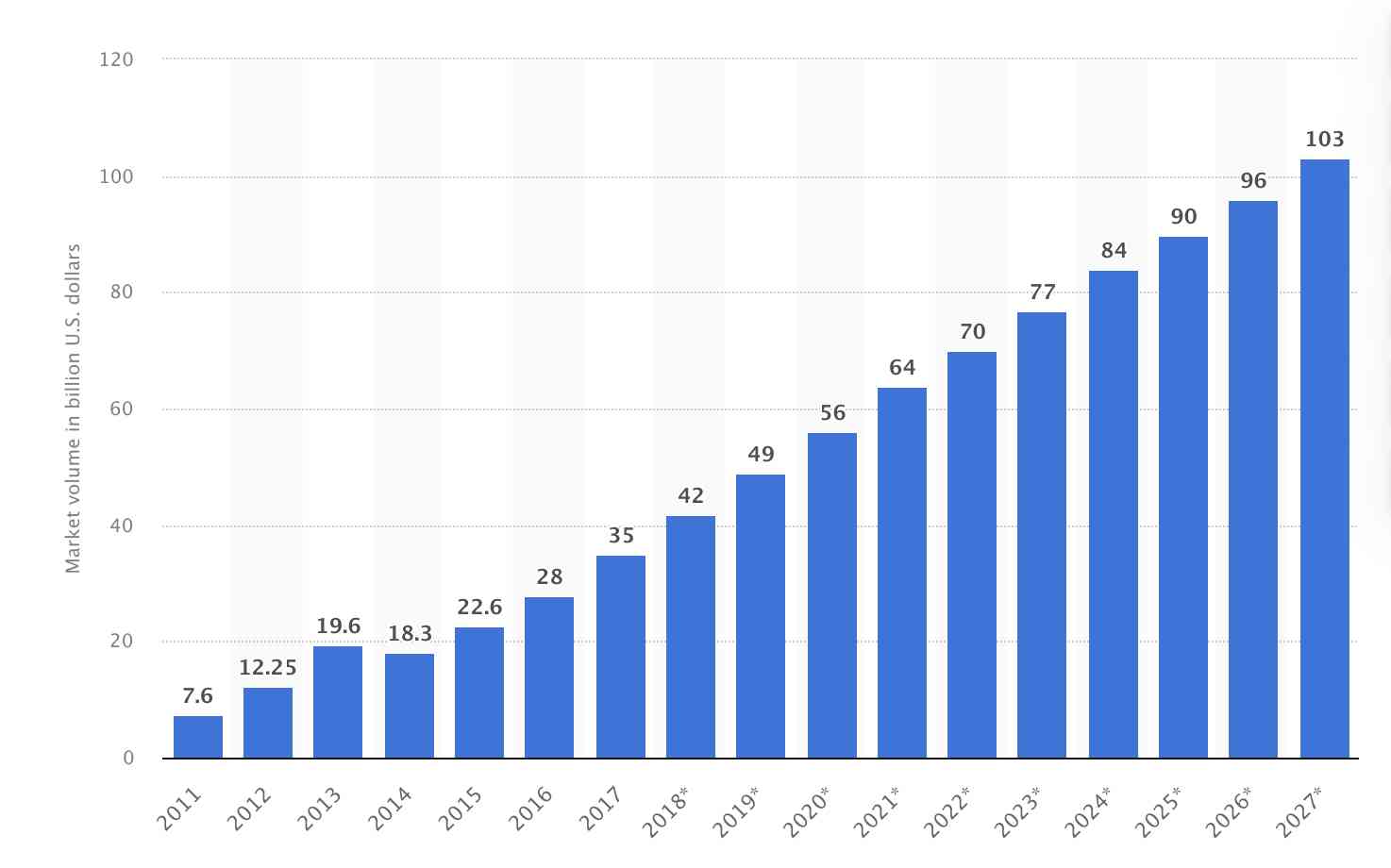
This market value indicates that there will be humungous amounts of data available in the future. Hence, the demand for data scientists will grow inevitably.
Further, the US Bureau of Labor Statistics forecasts an increase of 36% in the job market of the data science industry from 2021 to 2031 .
This growth has resulted in the popularity of the data scientist role. The U.S. News and World Report ranks this job #6 among the best technology jobs, #11 among the best STEM jobs, and #22 among the 100 best jobs.
There were some appealing numbers regarding the growth of the data science industry. With so much technological progress and growth in this field, you can experience a promising career.
Even if these growth numbers do not convince you, the salary of data scientists will undoubtedly appeal to you.
What is the Average Salary of a Data Scientist?
Experience, location, skillset, and company are the deciding factors for the salary. You can find different sources on the internet stating the average data scientist's salary. Let us briefly discuss this below.
- According to Glassdoor , the average base pay is $1.21 lakhs per annum, estimated based on 26,572 salaries.
- Meanwhile, PayScale states the average salary as $98,342/year based on 9,080 salary profiles. Also, the following table highlights the average salaries based on experience:
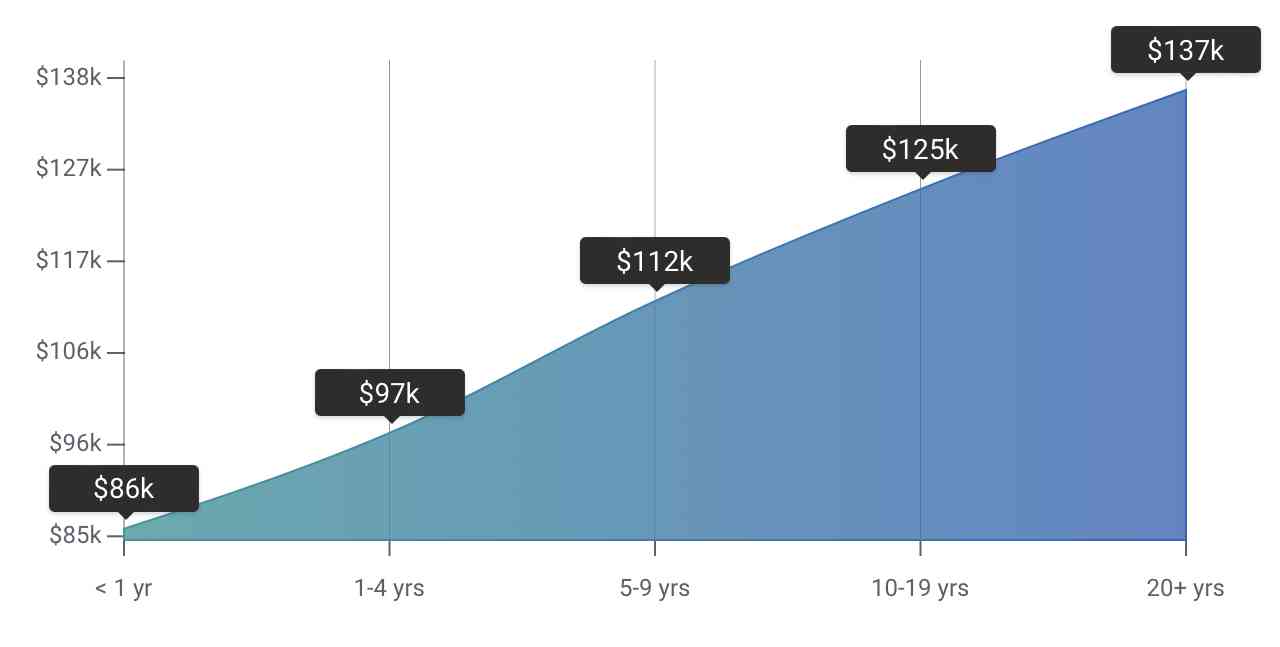
Skills also matter the most when deciding the salaries. The table below highlights the average salaries based on skills:
|
Skills |
Average Salary Per Annum |
|
Python |
$99,250 |
|
Machine learning |
$100,511 |
|
R |
$91,952 |
|
Data Analysis |
$99,250 |
|
Statistical Analysis |
$98,778 |
Conclusion
There is no doubt that data science is one of the most lucrative career options in the tech field. Of course, you must have a wide skill set and the will to face and overcome challenges to become a data scientist. As the world is heading towards an age where huge loads of data are commonplace, the importance of a data scientist is only meant to rise.
So, if you think you are up for the challenges of dealing with loads of data, welcome to the world of data science.
All the best!
People are also reading:



Leave a Comment on this Post